前面有几篇文章讲了数据仓库建设的方法和思路,覆盖了数据仓库设计过程中的多数要素。到了具体的落地实践方面,因为具体业务、数据使用场景的要求以及人力物力等因素的影响,实现的方案非常多样。如今大数据分布式存储引擎和计算引擎有多种成熟的选择,相互之间各有优势,各家公司在实际使用过程中也都会各有偏好。我选取了一些我通过在各种论坛活动上了解到的,以及在网上或者书上看到的多家互联网公司的数据仓库落地方案,分类梳理了一下,希望能给数据仓库设计者包括自己一些新的思路。
因为各种方案的组件的选择和设计思路都有比较大的差异,选择这些落地方案的分类方式确实让我纠结了一会,最后决定用核心组件(主要是数据明细层DWD的选择组件)的类型来划分。描述过程中的一些词汇都是我在前面几篇文章中提到的,跟原本的数据架构设计者的提法并不一定相同,但是并不影响意思的表达。另外,下文中选取的架构图都标明了出处,侵删。
Hive/HDFS
Hive的设计目标就包括了为数据仓库提供服务,并且在业内的接受程度也最好,因此是选用最多的数据仓库组件,包括美团点评、京东、唯品会等。Hive的优势包括可以支持超大数据量的分布式存储,有配套的ETL方案,以及对sql的良好支持。在很多场景下,hive还会跟Presto、Druid、Impala配合使用。
如下图,来自美团在2016年的大数据架构图
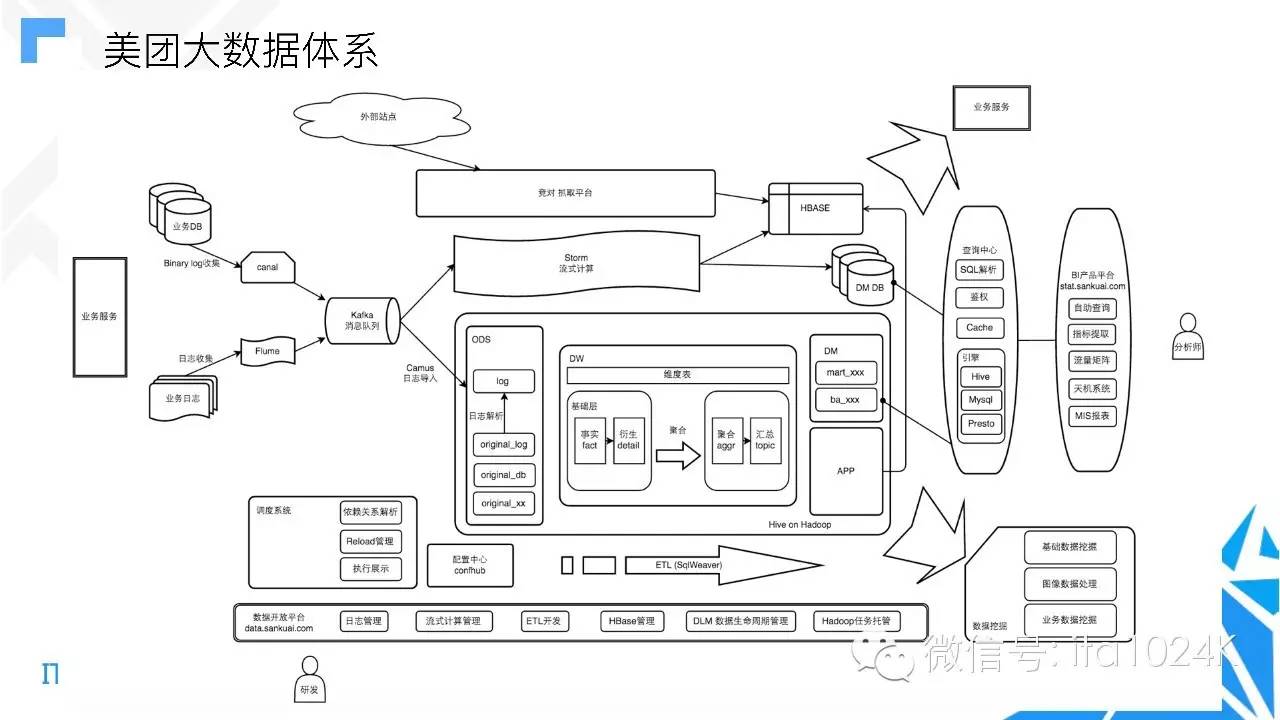
图中可以看到当时美团也是用了四层的数据仓库分层,并且所有的数据都存储在hive上。
再比如下图是唯品会的架构图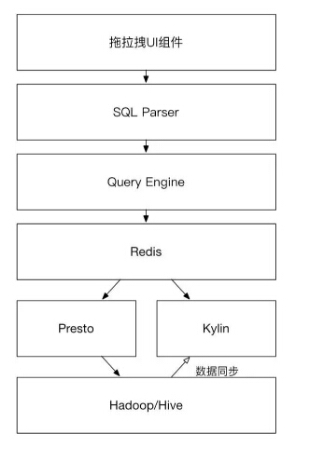
这里虽然没有细节,但是数据明细层依然是使用了HIVE,这个架构图的重点在于DWD和DWS层对OLAP的支持,追求的是查询的快速和大量响应,因此在presto的基础上增加kylin,并且路由确定数据源。Kylin作为一个支持多维cube预计算的工具,在数据仓库系统中使用的也非常广泛。
Kudu
Kudu是最近开始觉得的分布式存储组件,在数据分析和随机读取的响应速度方面都明显的超过hive,统一也厚很好的sql支持。网易使用Kudu作为数据仓库的核心组件。
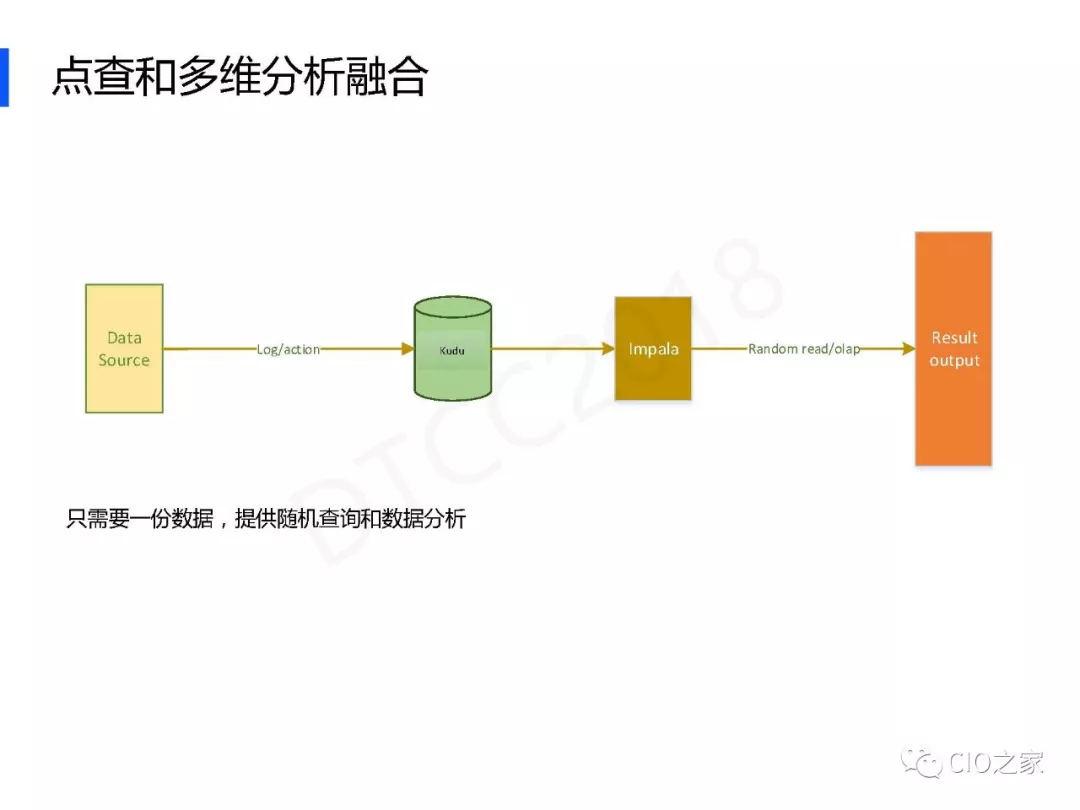
网易的架构也是从HDFS/Parquet升级而来,主要目的是增加实时性和融合离线数仓和实时数仓。具体可以参考这里和这里
Hbase
Hbase作为一个nosql的数据库,查询性能超过Hive和Kudu,因此经常被用作实现实时数据仓库,例如上面提到的美团和网易在使用Kudu前的方案。同时因为hbase可以跟Pheonix结合提供sql支持,也被有些公司用作离线和实时的融合方案。这个方案的缺点是,因为在不命中rowKey和索引的情况下,需要全表扫描,在数据量过大的时候会带来瓶颈。数据量在PB以下,对查询做一些适当限制的情况下,应该可以很好的支持。
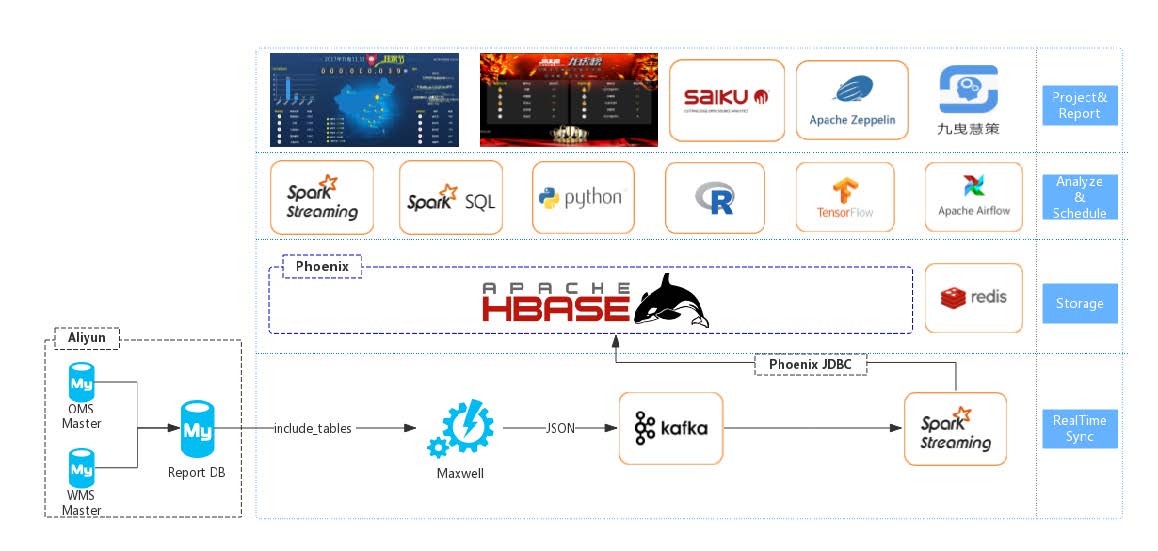
如下图是使用hbase作为核心组件的架构图。来源是这里
自研
当然,大厂还可以采取自研的方式,例如阿里的OneData。下图架构图来自于《大数据之路:阿里巴巴大数据实现》
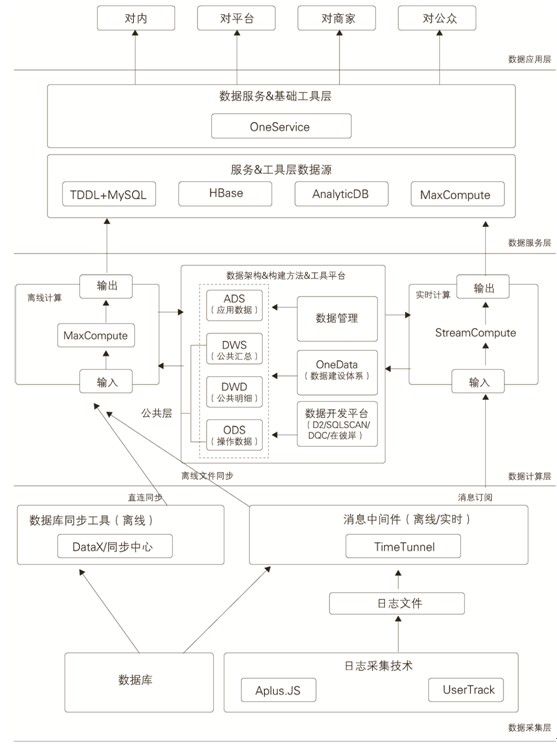
如上图中,阿里也是采用了比较经典的四层架构。