数据仓库的概念已经提出很多年,在之前还有一个“决策支撑系统”的叫法。在这漫长的岁月里,工程师和学者提出了很多的方法论和技巧。到了现在,大数据的技术栈到了以hadoop为主的年代,kimball的维度建模理论是被接受和使用最广泛的方法论。
维度建模的概念并不是kimball的原创,是由他带到了数据仓库的建设理论之中。所以这整套理论的核心,也不仅仅是维度建模的思想,还有附带的一系列原则、方法和技巧。当然还需要注意点是,这些原则和方法大多是从实践中总结出来的。我们的主流技术栈已经不同,这些经典的内容也已经不能生硬的照搬,要根据自己的技术栈和业务特点做一些适应性的变化。不过,这并影响kimball的维度建模给我们当前的数据仓库建设工作起到了很大的参考和引导作用。
这篇文章希望通过几个维度建模的核心词汇为引导,介绍维度建模对我们最有用的内容。
1. 事实表和维度表
维度建模的方案不采用我们熟悉的三范式对数据进行建模。三范式的数据建模方式很适合操作数据库和事务数据库,但是随着业务的变复杂,三范式数据库的关联会形成一张很大的关系图,给分析人员使用带了很大的困难。
维度建模任务,我们所有对数据的使用都在想从某个角度得到一个度量,所以把表分成事实表和维度表两类。
维度表是对环境的描述,提供了对数据分析的各种角度。事实表中则是需要被度量的内容,以及跟各种维度的关联关系。
在进行维度建模的时候,一般包括这几个步骤:1. 确定业务的领域和主题; 2. 确定需要的分析维度,补充所需维度表;3. 确定事实表度量 4.ETL设计和开发
2. 星型模式
当事实表和维度表通过关联键联系到一起,数据模型就形成了星型,类似下图这样。
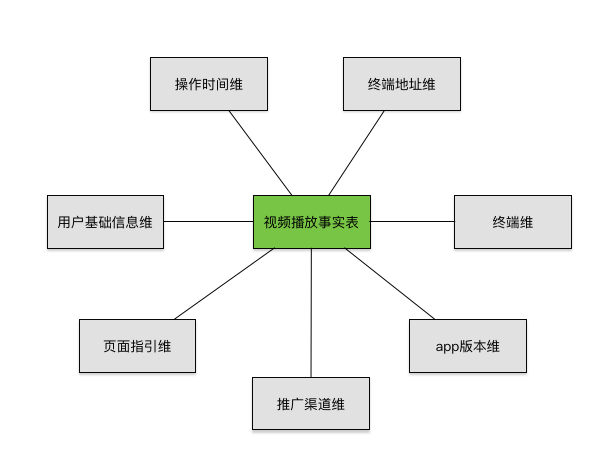
星型模型的最对数据使用者非常友好,因为足够简单。在数据仓库的建设中,简单是一个很好的特征。除了星型模型之外,还有一种雪花模型,就是在维度表上关联更多的维度表。但是如果基于简答的原则,这种方式是不推荐的。例如上图中的终端地址维度,其实可以看做是跟终端维度关联的,但是我们坚持采用星型模式,因此终端地址维度也被直接关联到了事实表上。
3. 一致性
一致性是维度建模能够成功的前提,主要分为两个方面:
- 事实一致性。如果多个事实表中出现的同样的度量,他们之间的含义要是一样的,这个是数据仓库可信度的保证
- 维度一致性。维度表的设计必须是面向这个数据仓库统一考虑的,在不同事实需要同样的分析角度时,关联的是同样的维度表。这样能够做到在汇总层面把多种事实的度量融合到一起。
4. 敏捷开发
能够支撑敏捷开发,可能是kimball维度建模能够在当今的互联网公司中大受欢迎的一个重要原因。或许在提出之初,kimball并没有把这个当做是核心特性,而现在,这种可以从下往的开发落地的特征却成了这一方法被大家采用的基础。这个也是Kimball的维度建模和Inmon的数据仓库建模方法相比最大的区别之一。
在前面的一篇文章中,我提到数据仓库的设计者需要从顶向下,面向业务整体。这跟现在我们说的维度建模的方案可以自下而上的支撑敏捷开发并不冲突。从顶往下是对数据仓库的设计者思考模式的一种建议,是希望设计者拥有业务角度的大局观,为数据仓库的建设确定一个完整的目标。这个建议对采用维度建模的数据仓库设计者更加适用。因为采用维度建模的设计者,如果缺乏业务视角,可能会导致数据仓库长期都是不完整的、不权威的。换句话说,从顶往下的模式是一种建议而不是必须遵守的规范。在实际执行落地过程中,采取维度建模的数据仓库是可以采用的敏捷的方式一步步的去完善,一步步的向完整、可信前进。